This article was originally posted on Substack by Nick Hellemans, head of product at Awell.
In 2023, AI and Large Language Models (LLMs) have claimed the spotlights, dominating headlines and sparking widespread discussions. We will see the technology evolving over the next couple of years, and if it keeps evolving at the same pace as it has been doing in the past 12-18 months then we are in for a hell of a ride 🎢.
If you are a technology company and you haven’t been doing anything with AI in the past year then you are missing out and will probably have a significant disadvantage compared to your competitors who are leveraging it. Even in your day-to-day work, tools like ChatGPT can really make you more productive.
AI Won’t Replace Humans — But Humans With AI Will Replace Humans Without AI
Source: Harvard Business Review
LLMs
This post focuses on a subset of generative AI: the LLMs. Sometimes people tend to have a wild imagination of what LLMs are and how they work, and therefore use them for the wrong purpose (I am guilty of that too). So let’s quickly recap what an LLM is and how they work.
LLMs are models that can generate text. They work by guessing the next word, assigning a chance or probability to each possible word that might come after a given prompt, and based on the context.
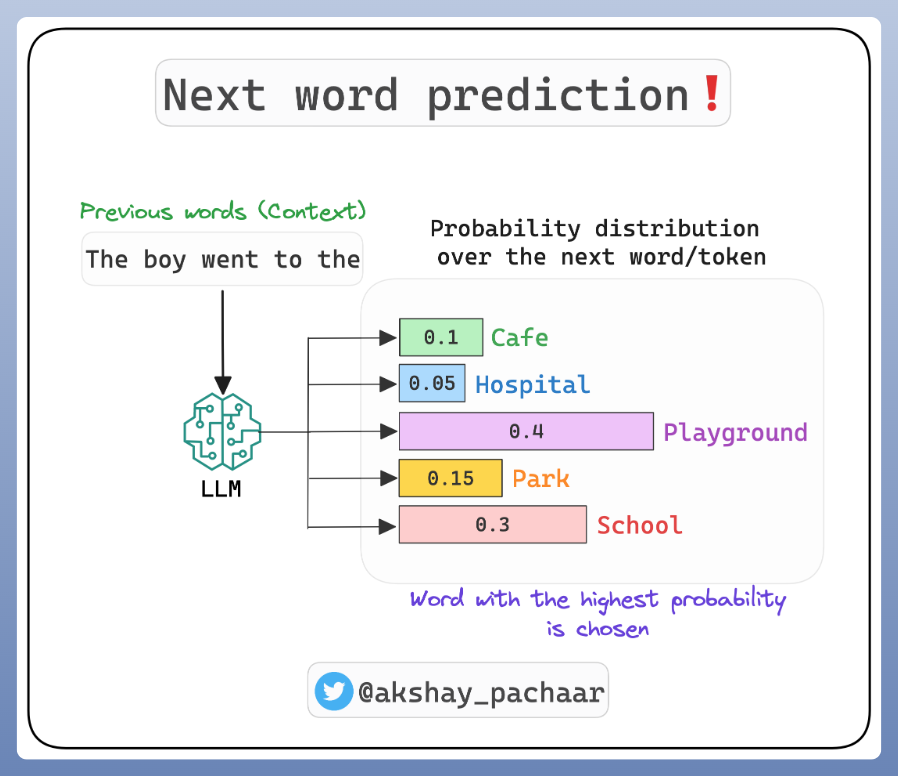
The Project
During the summer of 2023, we organized a “Make yourself or our customers more productive with AI”-week at Awell. We basically told everyone in the company to spend a full week researching or experimenting with AI. If it would help them deliver something they were currently working on, fine. If that meant deprioritising some of the planned work, also fine. The only rule we had was that at the end of the week, everyone presented their findings or projects in our weekly Show & Tell.

when its your turn for show and tell but you have nothing to show and tell - Donald Trump Says | Make a Meme When you are in BAU mode, setting aside time for learning and venturing into new areas can be tough. After all, there are so many things to do and we tend to be sucked into the business all the time. Having this kind of Hackathon-vibe for a week where we gave people the mandate to experiment without the pressure to deliver was really a forcing device to make sure people would go out there and learn about how the technology could impact their or our customers’ day-to-day lives and make them more productive. Spoiler: the results at the end of the week were amazing 🤯.
During that week, I took a swing at making our developer documentation more accessible. The idea was to create a Chatbot-like interface where you could ask questions in natural language about our developer documentation.
The future press release looked like this:
Sick of playing hide-and-seek with the information you need for integration with Awell? Meet AvaGPT, your go-to digital aide to help you build with and on top of Awell. Just type in your question and consider it answered—Ava scans our entire Developer Hub and takes you straight to the gold.
I would like to share the journey we went through setting this up. With all the information below, I believe you should be able to set up something similar within a day.
Hat Tip 🎩
Credits to Rik (Awell) and Brendan (Flexpa) as Rik discovered FlexpaGPT earlier this year and Brendan was so kind to share some of the implementation details of how they’ve built it. We ended up using similar strategies and technologies to build it.
What Do We Need?
Let’s start by mapping out what we need to get this project going. I.e. what are the main elements of the solution? 🛠️
- A prompt: We need a front end where users can type a question and where we can print an answer. The idea is to have a Chat-like experience like ChatGPT from OpenAI.
- Context: In this use case, the context is all of the documentation on our Developer Hub. If the LLM doesn’t know what information is on our Dev Hub, then it won’t be able to formulate an answer.
- An interface or model that executes the prompt against the provided context and returns an answer in natural language.
Buy vs. Build
I realized fairly quickly I wanted to leverage a 3rd party tool to get something going quickly. Luckily, with the increasing prominence of AI and LLMs, a wave of new SaaS companies has emerged like mushrooms after a rain, offering services harnessing this technology.

Thanks to Brendan at Flexpa, we discovered Markprompt, an early-stage start-up providing AI prompts for your docs. When reading their website and docs, they seemed a really good fit:
Markprompt is three things:
- A set of API endpoints that allow you to index your content and create LLM-powered apps on top of it, such as a a prompt.
- A web dashboard that makes it easy to set up syncing with content sources, such as a GitHub repo or a website, drag and drop files to train, …
- A set of UI components in React (and other frameworks) that make it easy to integrate a prompt on your existing site.
Looking back at our “What Do We Need?” section, it looked like they had a solution for all of our requirements. That sounds like a no-brainer to me 🧠.
You can learn more about Markprompt and how they process and query content here.
Using Markprompt
The Context
The context is all of the documentation on our Developer Hub. If the LLM doesn’t know what information is on our Dev Hub, then it won’t be able to formulate an answer.
So we need a way to index all the content on our Developer Hub in Markprompt. Our Developer Hub is custom-built (View it on GitHub) and all the content is stored in Markdown files which shouldn’t make this too hard. After all, Markprompt natively supports working with Markdown files (what’s in a name, huh?).
Keep in mind that Markprompt offers different strategies to index your content:
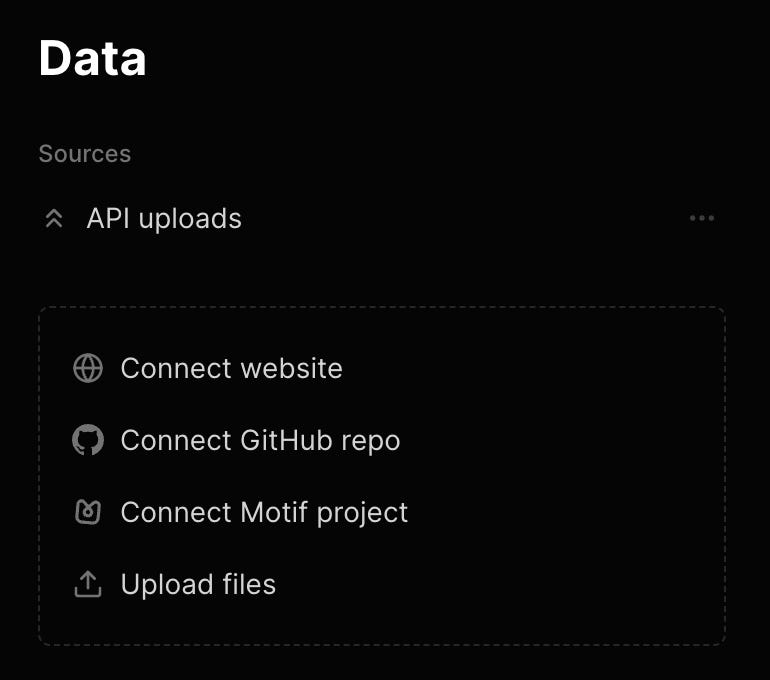
I decided to index content through their API as I saw a couple of benefits in doing so:
- I have full control over when and how I would like to index content.
- We can use GitHub Actions to make the indexing part of our CI/CD pipeline. This means that when content is updated and deployed, we can automatically retrain the model.
- 🤫 I want to have the feeling I still built something myself, after all, I am a builder and builders just love building.
Setting up the GitHub Action
So the idea was to create a GitHub action that would gather content from all the Markdown files and send it to Markprompt using their API. The API endpoint to index or train content can accept a file payload so we can upload a ZIP file that contains all of the Markdown files.
Some additional complexity I had to deal with is that some of our documentation is located in a different repository. More specifically, all of the documentation on Awell Extensions and our Marketplace lives in a separate repo but is surfaced in our Developer Hub via APIs. I wanted to make sure that documentation was indexed as well which meant I had to set up a GitHub action in two repositories.
The Markdown files in the Developer Hub had a pretty simple folder and file structure. Basically, all the Markdown files are located in the /content directory.
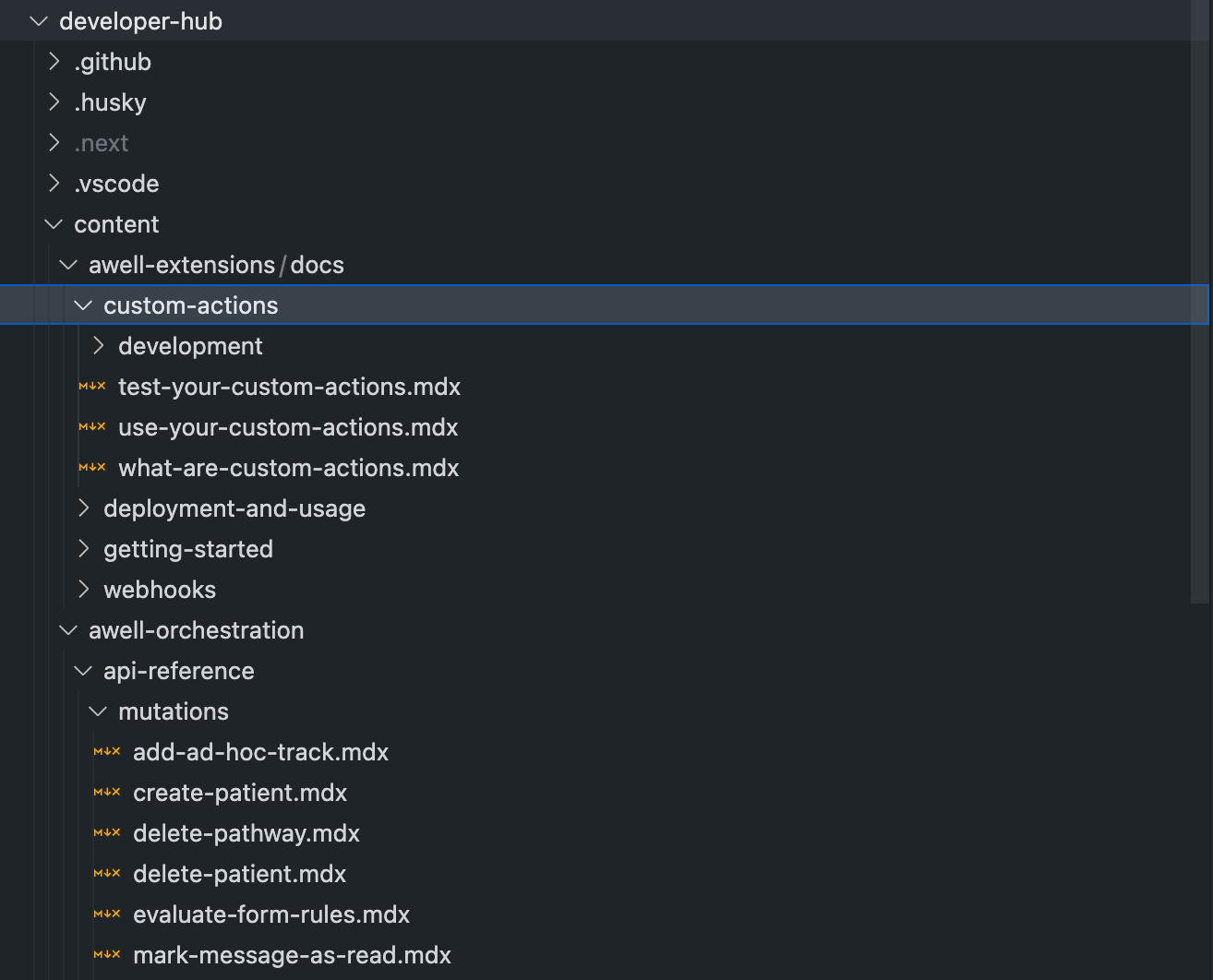
After some Googling, I found a GitHub action that pretty much worked out of the box:
Unfortunately, the file and folder structure in our Awell Extensions repository was a bit more complex:
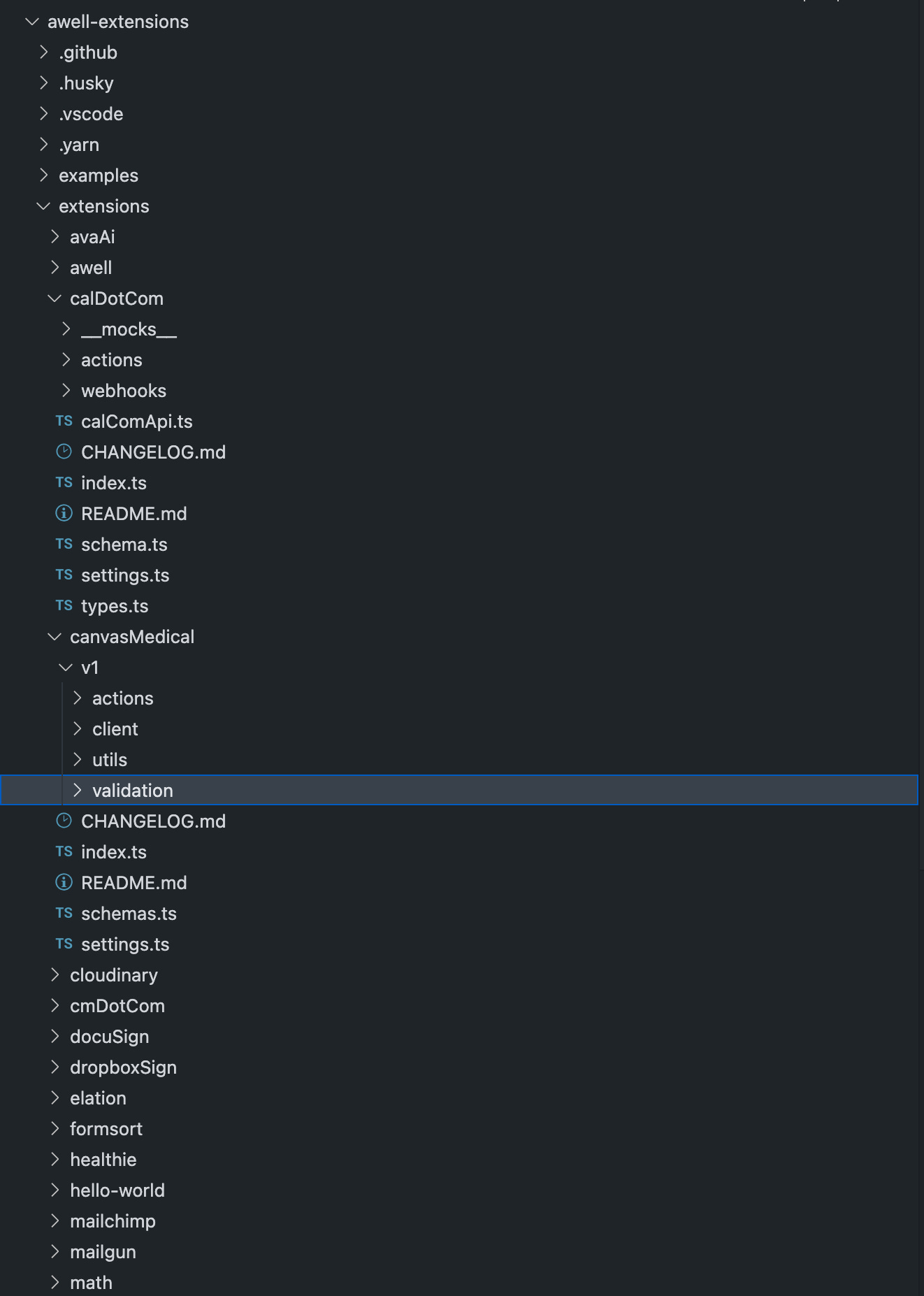
Here’s why:
- All extensions have a dedicated folder with a
README.mdfile that contains the documentation about that extension but there are also other Markdown files likeCHANGELOG.mdthat I don’t want to index. - All the files are called
README.mdwhich isn’t great for indexing. I would much rather have a name specific to the extension (e.g.:CanvasMedical.md). - I wanted to exclude some files, e.g. we have a hello-world extension and I don’t want that to be indexed.
Additionally, I wanted to generate a Marketplace.md file (which doesn’t exist) that simply lists all of the available extensions so it can be indexed as well. I figured that having a file indexed that explicitly listed all of the available extensions including their description would help with discoverability in case people would ask questions like: “What extensions are available in the Marketplace?” or “What extensions does Awell have with communication providers?”.
So I had to adapt the GitHub action a bit to accommodate these requirements.
If you’re still building GitHub actions from scratch, please don’t. Nobody likes doing that and it can be a pretty tedious and frustrating process too. As mentioned in the intro of this post, if you are not leveraging AI yourself then you are missing out on some serious productivity gains. So let’s leverage ChatGPT to adapt the GitHub action for us!
I started by passing ChatGPT the working GitHub action from the first repository. If you start with an example (i.e. give it context), the outcome will be much better. I then started to have a back-and-forth conversation with ChatGPT to get the action into a shape where it did what I wanted it to do
You can find the full conversation I had with ChatGPT here in case you’re interested but below you can find a partial extract of that conversation.
And so on...
After a 5-minute chat, I ended up with a working GitHub action 🥳. Doing this manually would easily taken me an hour, I just got 55 minutes of my life back!
The Interface/Model
We need an interface that can execute the prompt against the provided context and returns an answer in natural language.
Now that Markprompt has indexed our documentation (i.e. it has context), we can just use the Markprompt API to execute a prompt against the provided context.
Markprompt provides a set of libraries that makes this very easy. If you want to build your own front end and just leverage a library that helps you with the API calls to Markprompt, then @markprompt/core is your best choice (more on other front-end options below).
The Prompt
We need a front end where users can type their questions and where we can display the answers. The idea is to have a Chat-like experience like ChatGPT from OpenAI.
Markprompt has a library with a set of prebuilt React components that should get you going quickly and in most cases would do the job just fine. I had some issues with adapting the styling to our needs and getting it to work well with how we are handling our dark theme so I decided to build a custom front-end component with a hook that leverages the functions available in @markprompt/core to communicate with Markprompt’s API.
Because we are using TailwindCSS, building and styling this component wasn’t too difficult as there are many Chatbot-like UIs available on the internet that are built with Tailwind. Because of Tailwind’s utility-first approach, the process of understanding and implementing design patterns from other websites is a breeze and we can easily adapt and integrate these styles into our own project. I believe we started with what our friends at Flexpa had (they use Tailwind too) and adapted it to our own needs and added some animations 😎.
I won’t bother you too much with the details here. The code is available online, so feel free to have a look!
Demo
Learnings
AvaGPT (how we called this feature) is now live for a couple of weeks and I think it’s useful to share some of our learnings and takeaways:
- Hallucination: although in the majority of the cases, it provides answers that are accurate and helpful, we have seen it hallucinating from time to time or providing an answer that’s a hodgepodge of content that the model thinks is related but actually isn’t. It might be a sign that our documentation is not always clear enough or it could be a result of how Markprompts indexes and searches content.
- Response transparency: probably one of the features we appreciate the most in Markprompt is the transparency they provide on what sources of content were used to provide the answer. Additionally, Markprompt has a feature that allows users to rate their answers (👎 or 👍) which could be used to improve the model (tho I don’t think they currently do that).
- Currently, AvaGPT co-exists with our search which is powered by Algolia. Both serve a similar job to be done: help users access information. But I do think there’s an important difference between the two. While the search feature can still be a trusty companion when you have a precise question or keyword in mind, AvaGPT thrives in situations where answers aren't readily or explicitly found in the documentation. It excels in piecing together information from various sources to provide you with comprehensive answers. Moreover, AvaGPT can even generate fresh content based on existing documentation (e.g. generate code samples in a programming language that is not documented on our Developer Hub).
- AvaGPT is only trained on our external-facing developer documentation. But usually, companies will have many more sources of documentation: internal documentation (Confluence, Notion, …), help centers for product documentation (Intercom, ZenDesk, …), etc. It would be extremely powerful if there’s a tool out there that can aggregate content from multiple sources with an easy-to-use API to launch prompts against the indexed content or trained model. That way, we can also choose what type of interface we would like to expose depending on the audience using it:
- Slackbot for internal employees to make information more accessible. This would be extremely helpful for onboarding, training, etc
- Chatbot in our apps and Developer Hub
I hope this was helpful. Don’t hesitate to reach out if you have any questions. I am also curious to learn about different solutions others have used to solve a similar problem.